
It’s been almost a month since my last blog post and my excuse is that I’ve been quite busy! So as today marks the end of my first PhD research rotation with Dr. Netanel Raviv, this blog post will consists of my work during the rotation and some thoughts regarding it.
As I explained in my last blog post, my rotation with Dr. Raviv dealt with exploring whether there exists a better means of coding a perceptron with improved minimum distance and relative distance than a parity code. This can be formulated equivalently by proving the existence of a 

where 

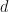
Our method of approaching this proof consisted of picking the generator matrix at random, computing the probability that one 

The generator matrix is a 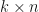


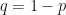


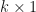


My initial attempt at this proof was an utter failure as I failed to take into consideration that we are working in 
 | 0 | 1 |
| 0 | 0 | 1 |
| 1 | 1 | 0 |
 | 0 | 1 |
| 0 | 0 | 0 |
| 0 | 0 | 1 |
Fixing this stupid error on my part, I found the probability that the $\latex i^{th}$ entry evaluates to 1. Since the 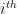
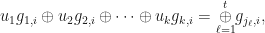
where 
![P[\overset{t}{\underset{\ell=1}{\oplus}} g_{j_\ell,i} = 1] = \sum_{\underset{n \textrm{ is odd }}{n=1}}^{t} \textrm{Binom}(t,n).](https://s0.wp.com/latex.php?latex=P%5B%5Coverset%7Bt%7D%7B%5Cunderset%7B%5Cell%3D1%7D%7B%5Coplus%7D%7D+g_%7Bj_%5Cell%2Ci%7D+%3D+1%5D+%3D+%5Csum_%7B%5Cunderset%7Bn+%5Ctextrm%7B+is+odd+%7D%7D%7Bn%3D1%7D%7D%5E%7Bt%7D+%5Ctextrm%7BBinom%7D%28t%2Cn%29.&bg=ffffff&fg=111111&s=0&c=20201002)
We will define this as 


![P[\textrm{light } \mathbf{u}G] = \sum_{i=1}^{\lfloor \frac{n}{2} + d - 1 \rfloor} \textrm{Binom}(n,i)](https://s0.wp.com/latex.php?latex=P%5B%5Ctextrm%7Blight+%7D+%5Cmathbf%7Bu%7DG%5D+%3D+%5Csum_%7Bi%3D1%7D%5E%7B%5Clfloor+%5Cfrac%7Bn%7D%7B2%7D+%2B+d+-+1+%5Crfloor%7D+%5Ctextrm%7BBinom%7D%28n%2Ci%29&bg=ffffff&fg=111111&s=0&c=20201002)
where 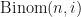
The “good” event for one information word 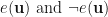
![P[E] = P[\underset{\mathbf{u} \in F_2^k}{\bigcap} e(\mathbf{u})]](https://s0.wp.com/latex.php?latex=P%5BE%5D+%3D+P%5B%5Cunderset%7B%5Cmathbf%7Bu%7D+%5Cin+F_2%5Ek%7D%7B%5Cbigcap%7D+e%28%5Cmathbf%7Bu%7D%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
where we want to show ![P[E] > 0](https://s0.wp.com/latex.php?latex=P%5BE%5D+%3E+0&bg=ffffff&fg=111111&s=0&c=20201002)
![P[E^c] = P[\underset{\mathbf{u} \in F_2^k}{\bigcup} \neg e(\mathbf{u})],](https://s0.wp.com/latex.php?latex=P%5BE%5Ec%5D+%3D+P%5B%5Cunderset%7B%5Cmathbf%7Bu%7D+%5Cin+F_2%5Ek%7D%7B%5Cbigcup%7D+%5Cneg+e%28%5Cmathbf%7Bu%7D%29%5D%2C&bg=ffffff&fg=111111&s=0&c=20201002)
and show that ![P[E^c] < 1](https://s0.wp.com/latex.php?latex=P%5BE%5Ec%5D+%3C+1&bg=ffffff&fg=111111&s=0&c=20201002)
![P[\underset{\mathbf{u} \in F_2^k}{\bigcup} \neg e(\mathbf{u})] \leq \sum_{\mathbf{u} \in F_2^k} P[\neg e(\mathbf{u})] < 1.](https://s0.wp.com/latex.php?latex=P%5B%5Cunderset%7B%5Cmathbf%7Bu%7D+%5Cin+F_2%5Ek%7D%7B%5Cbigcup%7D+%5Cneg+e%28%5Cmathbf%7Bu%7D%29%5D+%5Cleq+%5Csum_%7B%5Cmathbf%7Bu%7D+%5Cin+F_2%5Ek%7D+P%5B%5Cneg+e%28%5Cmathbf%7Bu%7D%29%5D+%3C+1.&bg=ffffff&fg=111111&s=0&c=20201002)
Expanding out ![P[E^c]](https://s0.wp.com/latex.php?latex=P%5BE%5Ec%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![P[E^c] = \sum_{t=0}^{\lfloor \frac{k}{2}} {k \choose t} P[\textrm{heavy } \mathbf{u}G] + \sum_{t = \lceil \frac{k}{2} \rceil}^{k} {k \choose t} P[\textrm{light } \mathbf{u}G].](https://s0.wp.com/latex.php?latex=P%5BE%5Ec%5D+%3D+%5Csum_%7Bt%3D0%7D%5E%7B%5Clfloor+%5Cfrac%7Bk%7D%7B2%7D%7D+%7Bk+%5Cchoose+t%7D+P%5B%5Ctextrm%7Bheavy+%7D+%5Cmathbf%7Bu%7DG%5D+%2B+%5Csum_%7Bt+%3D+%5Clceil+%5Cfrac%7Bk%7D%7B2%7D+%5Crceil%7D%5E%7Bk%7D+%7Bk+%5Cchoose+t%7D+P%5B%5Ctextrm%7Blight+%7D+%5Cmathbf%7Bu%7DG%5D.&bg=ffffff&fg=111111&s=0&c=20201002)
I wrote a MATLAB script to test different values for the parameters 

I would have liked to continue investigating this disappointing result but at this time, my rotation with Dr. Raviv has come to an end and I must prepare for my next rotation with Dr. Neal Patwari in the ESE department. Regarding my thoughts on this rotation, it was my first time dealing with such theory-heavy research but I think I came to like this sort of work. It’s definitely a change from more practical and/or application-wise research and it relies heavily on math and probability theory (especially moreso as this is ML research). At this point, I’m not entirely sure if I would enjoy the idea of pursuing a theoretical research path for my PhD as it sort of limits the opportunities in industry after graduation. And at the moment, personally, I swing a bit more towards working in industry than staying in academia post-grad. Well, my next rotation with Dr. Patwari will be on the completely opposite spectrum where I will likely be developing a ML application so at the end of my second rotation I will have a better sense of the kind of research I enjoy. 🙂
